分享内容:
1.郭世晨:《Gated Convolutional Neural Network for Semantic Segmentation in High-Resolution Images》
2.Fyaz Ali:《Human Action Recognition in Videos》
1. 论文分享及工作汇报(郭世晨)
1)论文分享



2)工作汇报
Introduction
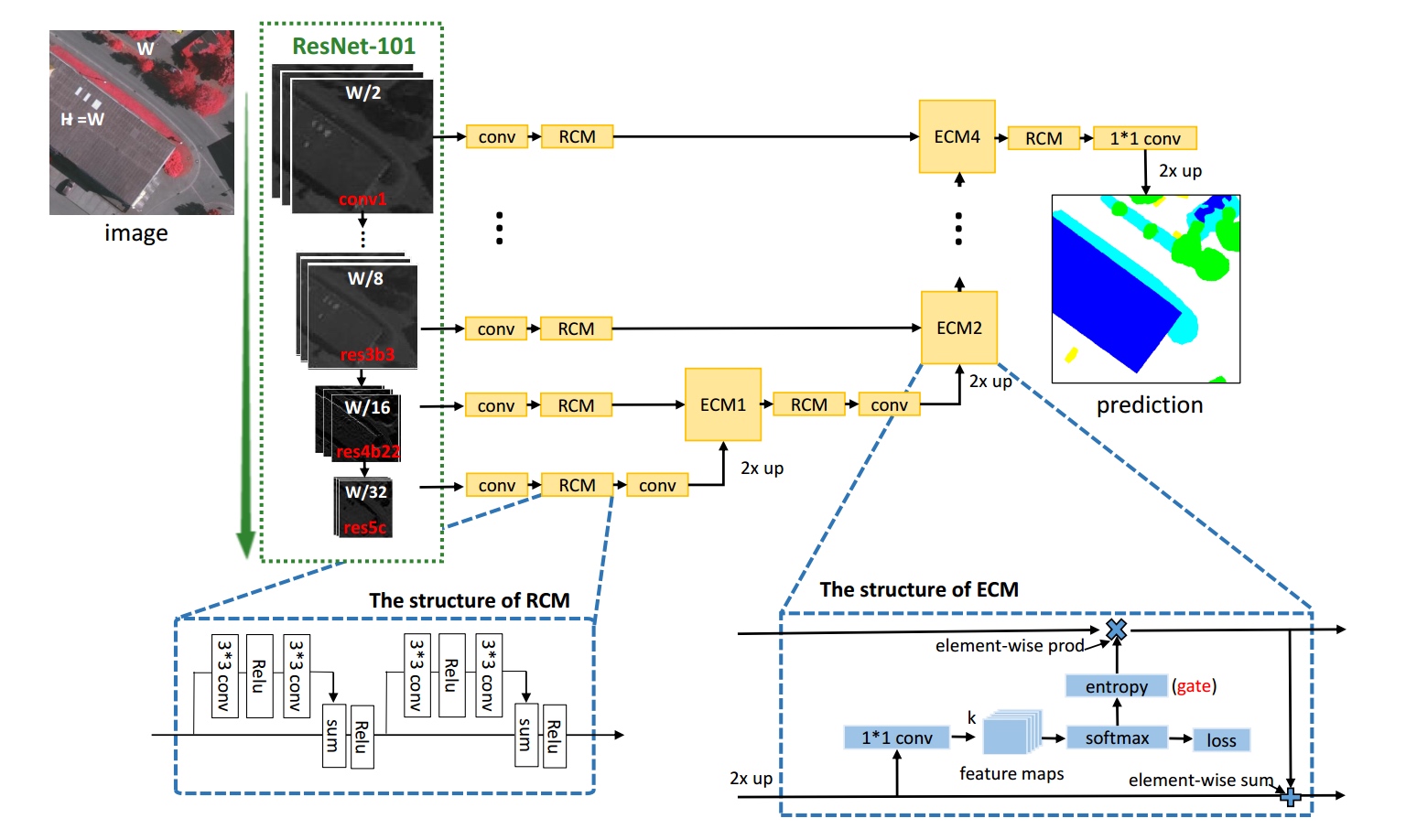
- 近年来, 深度学习在遥感图像的语义分割中得到了极大的应用, 然而不同物体尺寸变化范围较大的问题仍然是目前遥感图像语义分割主要存在的难点之一. 例如, 建筑、道路通常以大面积的形式出现, 而汽车这一类别不仅占地面积较小、而且分布分散, 导致物体边界区域较多, 而混沌现象往往就在边界发生. 此外, 由于汽车这一类别所占的总像素点较少, 所以被分错时产生的影响会增大, 直接影响分割精度.
Model
-
由于语义分割的网络框架都是采用“编码—解码”的方式构成的, 那么如何将底层特征与高层特征相互融合便是提高图像细节部位分割精度的主要方法. 前人[?]进行特征融合的手段要么是“简单的求和”, 要么是“简单的级联”.
在“简单的级联”过程中, 相当于学习下面公式中矩阵$\omega_1$与$\omega_2$, (即学习一个三维卷积核的参数) 而在“简单的求和”过程中, 公式被进一步简化, 相当于矩阵$\omega_1$与$\omega_2$的所有元素取值均是1
-
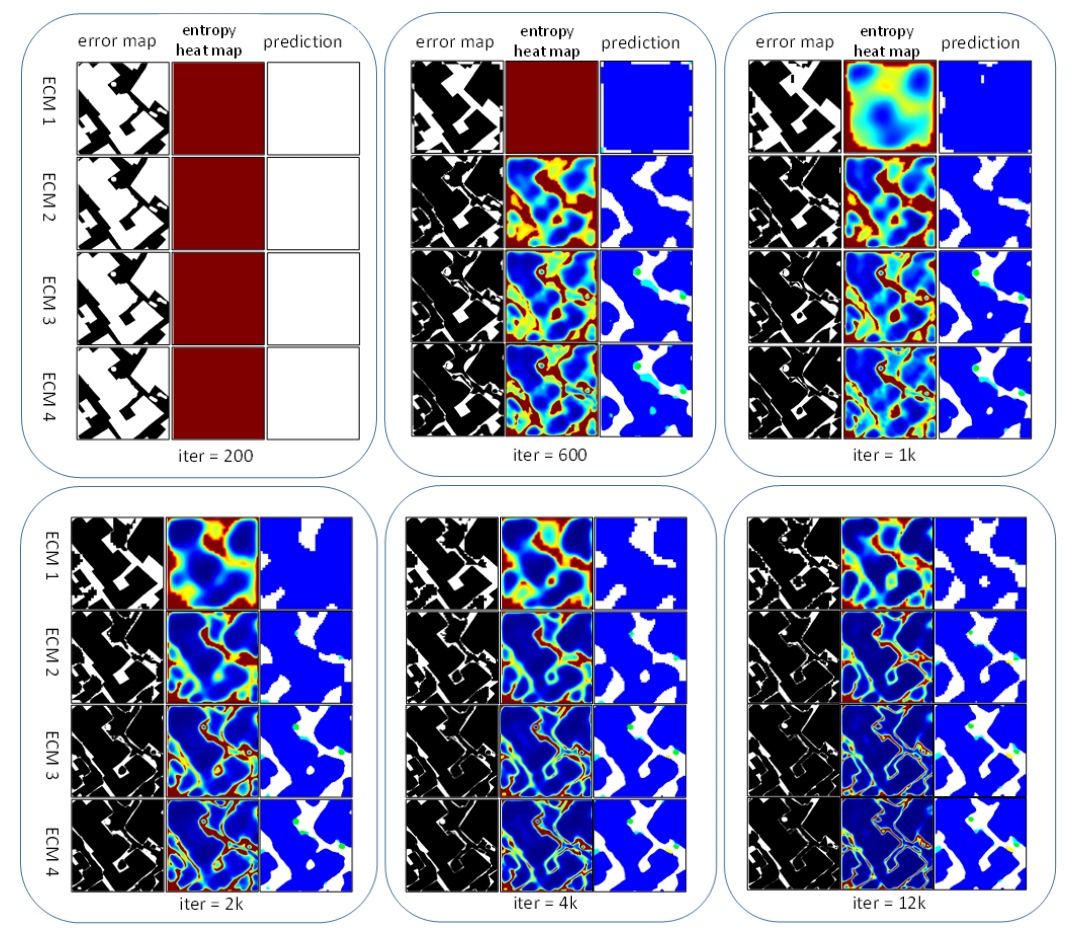
在深度学习中, 卷积核是从图像左上角依次滑动至图像右下角, 可见, “简单级联”与“简单求和”的缺点是不能针对每个像素点的状况做出动态调整. 在这里, 我们非常认可[?]的特征融合方式, 即将分割网络最后一层softmax后的概率值作为输入得到信息熵指标。
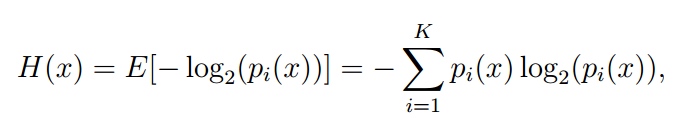
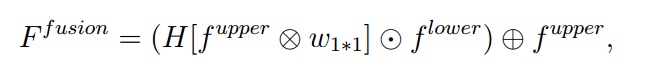
-
由上面的公式可见, 在[?]中, 做横向比较时, 不同的像素点享有不同的权重, 便于动态筛选特征; 然而, 做纵向比较时, 我们把目光只聚焦于一个像素点, $f^{lower}$在保持信息熵特性的基础上, 增大或减小是否会得到更好的分割精度呢?
-
从定性的角度分析, 我们认为信息熵在公式5的特征融合过程中起到了非常完美的选择作用和门控机制. 然而, 从定量的角度分析, 假设存在这样的一个指标(我们暂时称之为“更优指标”), 它具有如下三个特性:
- 1, 它可以与信息熵一样针对每个像素点做到动态筛选特征的作用,
- 2, 它的输入同样是softmax后的概率值
- 3, 它计算出来的指标数值比信息熵更大、或者是更小
那么, 将这样的指标作为底层特征的权重是否可以得到更好的分割精度呢? 我们无须探寻“更优指标”的具体数学公式, 只需要得到这个指标的泰勒展开式即可.
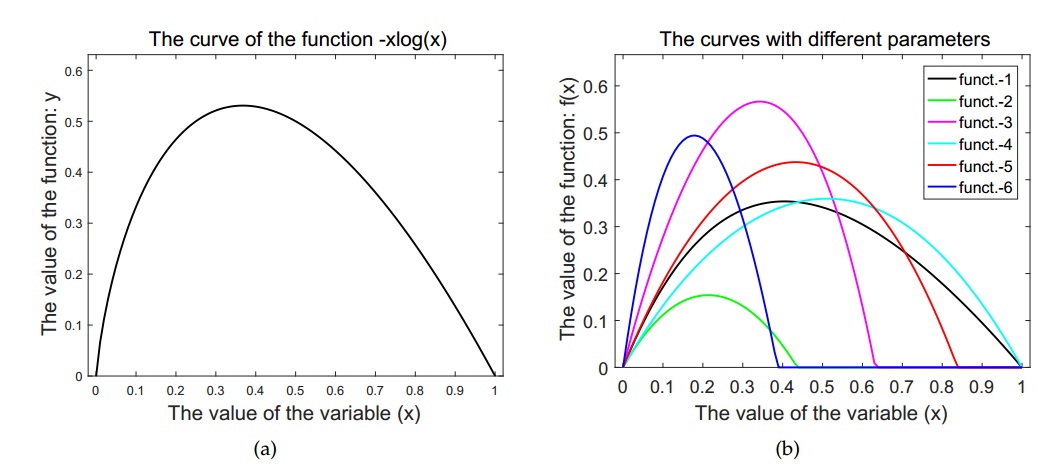
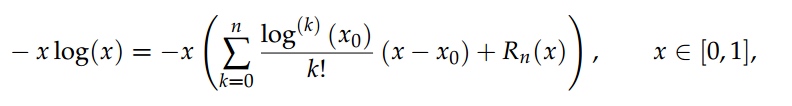
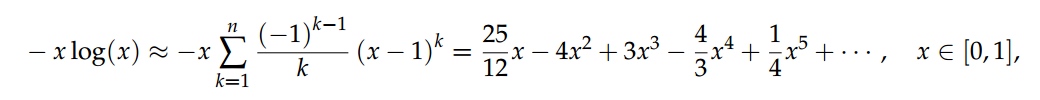
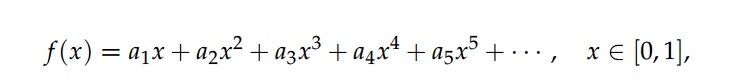
Advantage
- 第一, 在定性角度上分析, 本文模型继承了[?]动态选择特征的门控作用的优点, 为每一个像素点动态赋予权重, 起到门控的动态筛选作用. 在定量的角度上分析, 本文模型f_lower前的权重, 不局限于(0,1)的范围, 可以进行更大程度上的学习, 从而进一步提高分割精度.
- 第二, 本文模型继承了“简单级联”的优点——即特征融合过程中有参数可以学习,而不是像“简单求和”和[?]一样的套用固定公式.
- 第三, 相较于“简单级联”而言, 虽然CNN具有通过使用多个卷积核的方法来提升模型的能力, 但只有针对每一个像素点学习泰勒展开式时, 才可以利用到第一轮的分割概率结果, 使得有效的模型参数增多, 既能避免过拟合同时又能增强模型的表达能力.
- 第四, 相较于[?]而言, “更优指标”不是一个固定的公式, 它受softmax概率值与原始图像数据的共同影响, 使特征融合这一过程真正实现了由数据驱动、由数据指导.
论文中需要强调的是:
- 本文所研究的算法不局限于遥感图像, 在其他物体尺度大小不一的自然图像中依然可以使用
- 本章算法只利用了RGB图像,并没有使用高程数据(GSM)作为辅助数据,而且算法结果是单模型结果,并没有利用多模型融合策略。
Conclusion
本文从信息熵的角度出发, 但不仅仅局限于信息熵之中, 在充分继承信息熵门控作用的同时, 又进行了更大程度上的学习.
2. Human Action Recognition in Videos (Ali)
ABSTRACT
My thesis work explores various approaches using Convolutional and Recurrent Neural Networks to classify and temporally localize activities on videos, moreover an implementation to achieve it has been stated. As the first step, features have been extracted from video frames employing a state of the art 3D Convolutional Neural Network. These features are supplied into a recurrent neural network that solves the activity classification and temporally location tasks in a simplistic and flexible way. Different architectures and configurations have been tested in order to achieve the best performance and learning of the video dataset provided. In addition, it has been studied a different kind of post-processing over the trained network’s output to achieve better results on the temporal localization of activities on the videos. We show how our system can achieve competitive results in both tasks with a simple architecture. We evaluate our method in the ActivityNet Challenge 2016, achieving a 0.5874 mAP and a 0.2237 mAP in the classification and detection tasks, respectively. The results produced by proposed architecture in this thesis are very good and have state of art output.
Proposed Project:
The videos Recognizing activities becomes a hot topic over the last years in the computer vision area [1]. The exponential growth of portable video cameras and online multimedia repositories, as well as recent advances in video coding, storage, and computational resources, have motivated an exceptional analysis in the field towards new and extra efficient solutions for organizing, understanding and retrieving video content.
Deep learning and machine learning methods have recently become the hot topic in many computers vision tasks, such as objects and images recognition in still images. While successful techniques have been manifested with image understanding, video content still presents additional challenges (e.g. motion, temporal consistency, spatial location …) that usually cannot be bridged with a still image recognition solutions.
The goal of this report is to address the challenges of video content analysis taking advantage of state-of-the-art deep learning techniques. The aim of this project is to develop a competitive framework to both classify and temporally localize activities on videos. To accomplish this goal, the dataset used to fulfill this task is be the ActivityNet dataset [2], which offers untrimmed videos depicting a diversity of human activities.
In appropriate, this project’s main contributions are:
- The design and training of a deep learning model architecture, using 3D Convolutional features and Recurrent Neural Networks.
- This development and analysis of post-processing procedures for classification and temporal localization
- The statement of an open sourced package containing all the tools to reproduce the experiments, as well as the conversion of a state-of-the-art C3D model from Caffe to Keras.
I had already worked on deep learning and image processing techniques for still images, but never before in video analytics.
Requirements
This project has been finished with the certain goal of setting a baseline for video analytic with deep learning in the research so that future students and researchers to keep working on it. The specifications of this project are the following:
- Design and train a deep neural network to classify the activities and temporally localize it on videos using the ActivityNet Dataset.
This project first done by Image Processing Group (GPI) of the UniversitatPolit`ecnica de Catalunya (UPC) during the Spring 2016 semester so we worked on the same specification in order to improve some results. The specifications were selected to take into account the needs of the project and the available resources. All the construction was done on Python using a very well-known framework which is Keras, also a pioneering use of this library in GPI. This Deep Learning wrapper facilitates the design and training of models over two computational frameworks: Theano [3]and TensorFlow [4]. Both projects support complex and high demanding computations over both CPU and GPU. For this project, Theano was used as back-end because at the time of developing this project, it was the only one that had implemented the convolution 3D and max-pooling 3D operations required for its development. In addition to the software, specific hardware was needed. The high critical computational resources needed to train neural networks required the use of GPUs provided by the Software Lab UESTC.
Methods and Procedures
This project seeks to offer a simple and flexible solution to face the jobs of classification and temporal localization on videos. The proposed solution is made by a first step stage where the video features are extracted. To do so, to extract features from spatial and temporal dimension from video frames. We used a pre-trained 3D convolutional network. In parallel, features from audio were extracted to combine them with the ones extracted from the video frames.
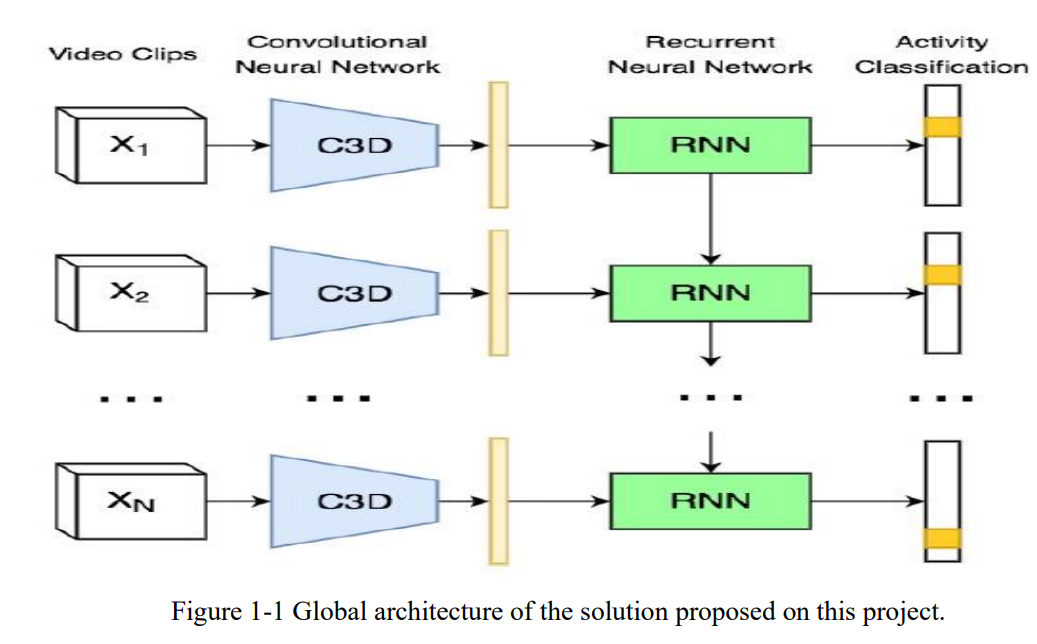
As a second step, a Recurrent Neural Network is proposed to exploit long-term relations and predict the sequence of activities available at each video. This network was tested with different architecture inputs. as shown in Below schematic diagram.Fig.1.1
All the experiments were done using a recently published video dataset, the ActivityNet [2]which offers untrimmed videos from 200 activities. All the videos from the dataset present a single activity on it so it’s possible to classify them globally. Furthermore, the activities along the video are temporally localized. Most of the effort and architecture was performed taking into account. Fixing the detection task can be easily extrapolated to solve the global classification task for the whole video.
Moreover, multiple post-processing techniques were proposed to improve the classification and detection tasks. Multiple configurations were tested for the purpose of maximize the results.
Finally, the very good results have been/img/presentation/2019-03-05/ taken using all these specifications.
Human Action Recognition
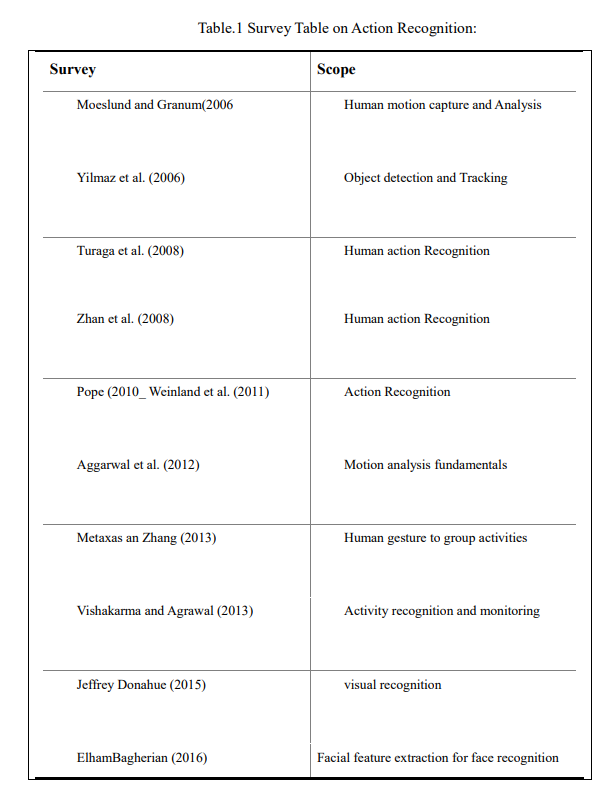
Analyzing motions and actions has a long history and attractive to various disciplines including psychology, biology and computer science (see Table.1 for the list of surveys related to motion and action recognition in computer vision). One can trace the fascination about motion back to 500BC with Zeno’s dichotomy paradox. From an engineering perspective, action recognition extends over a broad range of high-impact societal applications, from video surveillance to human-computer inter- action, retail analytics, user interface design, learning for robotics, web-video search and retrieval, medical diagnosis, quality-of-life improvement for elderly care, and sports analytics. The long list of emerging technologies and applications [6]points to “manually analyzing action and motion data is impossible”.
Human action recognition gets plenty applications in fields such as monitoring, security, sports, and movies. Such a method classifies a spatiotemporal feature descriptor of a human frame in a video, based on training examples. Nevertheless, many classifiers face the constraints of the long training sequence and the great size of the feature vector. Individual activity detection is a challenging, unsolved problem [7], [8], still though numerous attempts have been done. Human action analysis in computer vision includes detecting, tracking, and recognition of human activities [8]. This has a wide range of encouraging applications. Some examples are security surveillance, human-machine interaction, sports, video annotations, medical diagnostics and entry, exit control. However, it remains a challenging task to detect human activities, because of their shifting features and a wide range of poses that they can adopt [7].
Reference
- [1] JiquanNgiam, AdityaKhosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y Ng. Multimodal deep learning. In Proceedings of the 28th international conference on machine learning (ICML-11), pages 689–696, 2011.
- [2] Bernard Ghanem Fabian CabaHeilbron, Victor Escorcia and Juan Carlos Niebles. Activ- itynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, 2015.
- [3] Theano Development Team.Theano: A Python framework for fast computation of mathematical expressions. arXiv e-prints, abs/1605.02688, 2016.
- [4] Martın Abadi, AshishAgarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467, 2016.
- [5] Du Tran, LubomirBourdev, Rob Fergus, Lorenzo Torresani, and ManoharPaluri.Learning spatiotemporal features with 3d convolutional networks.arXiv preprintarXiv:1412.0767, 2014.
- [6] MdAtiqur RahmanAhad, JooKooi Tan, Hyoungseop Kim, and Seiji Ishikawa. Motion history image: its variants and applications. Machine Vision and Applications, 23, 2012
- [7] D. Tran, A. Sorokin, and D. Forsyth, “Human activity recognition with metric learning,” in Proceedings of the European Conference on Computer Vision, ser. LNCS 5302, vol. Part I. Marseille, France: Springer-Verlag Berlin Heidelberg, 2008, pp. 549–562.
- [8] J. K. Aggarwal and Q.Cai, “Human motion analysis: A review,” Com- puter Vision and Image Understanding, vol. 73, no. 3, pp. 428–440, March 1999.